

DiliTrust développe sa propre intelligence artificielle. L’équipe Machine Learning (ML) consacre ses journées au développement de cet outil unique.
La principale ressource de travail de l’équipe ML se trouve dans les contrats, puisqu’ils entraînent des modèles à reconnaître automatiquement les données contenues dans ces documents.
Dans cet article, nous vous aidons à comprendre le Traitement Automatique des Langues (ou TAL), domaine de l’intelligence artificielle qui permet d’analyser un texte et d’en déduire des informations pertinentes.
Le Traitement Automatique des Langues (TAL)
Le Traitement Automatique des Langues est un domaine de l’Intelligence Artificielle (IA) aux très nombreuses applications : du traducteur automatique capable de comprendre et traduire nos textes en plus d’une centaine de langues, à l’assistant personnel qui — conjointement aux technologies de Traitement de la Parole — permet de simplifier la prise nos rendez-vous et l’organisation nos calendriers.
Le TAL fait partie de ces domaines qui transforment continuellement notre quotidien.
En quoi consiste le TAL, plus exactement ?
Pour faire simple, le Traitement Automatique des Langues s’intéresse aux différentes manières d’analyser un texte et d’en déduire les informations pertinentes qui serviront de base à la création de systèmes capables de résoudre une variété de tâches plus ou moins complexes.
Ces tâches comprennent :
- la reconnaissance d’entités (e.g. détection automatique de noms, dates, montants…) ;
- les question-réponses (e.g. interrogation au sujet d’un évènement apparaissant dans le document) ;
- ou encore, la classification de texte (e.g. catégorisation automatique d’un courriel en spam/non-spam).
L’application du TAL dans le domaine juridique
L’utilisation du TAL sur une tâche unique représente souvent un intérêt limité, hormis en milieu académique où on s’intéresse surtout aux mécanismes de fonctionnement de ces méthodes.
En pratique, les applications plus concrètes du TAL tirent le maximum de ces technologies en construisant des systèmes plus complexes, ou pipelines, qui décomposent la problématique en une succession de tâches simples. Chacune de ces tâches est ensuite abordée via des méthodes d’apprentissage automatique (Machine Learning ou ML), ainsi que des règles assurant de la cohérence du tout.
Chez DiliTrust, nous proposons une solution simplifiant la gestion du cycle de vie contractuel (CLM ou Contract Lifecycle Management) qui intègre entre autres :
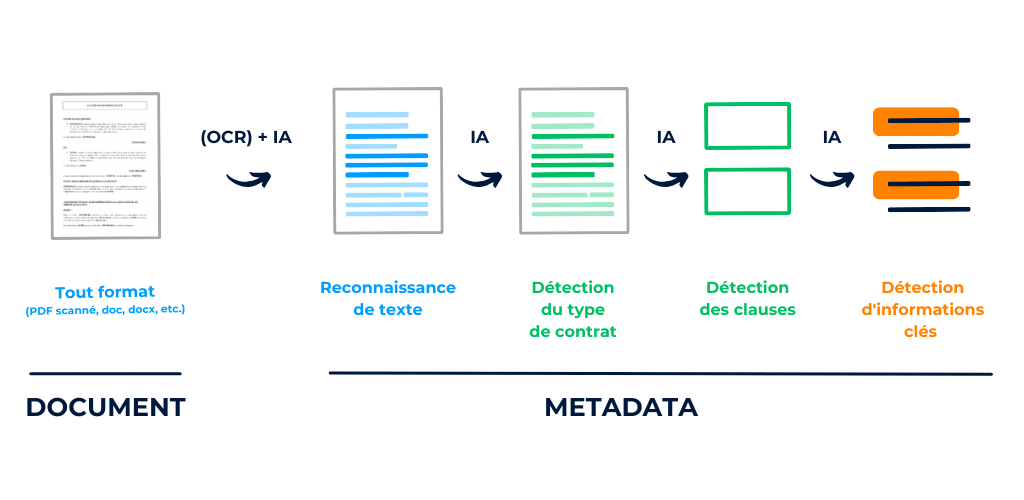
Illustration des étapes clés du pipeline d’analyse de contrats
Deux étapes clés en TAL : représentation et décision
Malgré la grande diversité de tâches que comprend le TAL, il existe essentiellement deux concepts clés qu’on retrouve quasi-systématiquement.
Le premier est celui de la représentation (ou encore vectorisation, plongement, …).
En effet, sous sa forme brute, le texte est inintelligible pour une machine et nécessite donc une transformation afin d’obtenir des valeurs numériques qui peuvent, elles, se prêter à différents calculs statistiques.
Étant données ces représentations, l’étape suivante consiste à effectuer ces calculs et à prendre une décision qui se manifestera sous diverses formes : classification, extraction d’information, …
Pour se familiariser avec ces deux concepts, nous allons étudier un cas concret de classification de texte qui nous permettra de voir comment construire un système capable de transformer des textes pour ensuite les catégoriser en différentes classes d’intérêt.
Critiques cinématographiques IMDb
Pour prendre en main les différentes méthodes du TAL, nous commençons ici par un cas standard de classification de texte. Plus exactement, on s’intéresse au jeu de données IMDb qui contient 50000 critiques cinématographiques postées sur le site du même nom.
Notre but sera de déterminer automatiquement si ces avis sont positifs ou négatifs. Il s’agit donc d’une classification binaire car nous ciblons exactement deux catégories.
Dans ce qui suit, nous utiliserons le langage de programmation Python afin de construire notre modèle d’analyse de sentiments.
Téléchargement des données
Tout d’abord, nous allons récupérer la base IMDb en exploitant l’outil datasets proposé par HuggingFace :
Aperçu des données

Nombre de documents par catégorie

Le jeu de données comprend deux parties, l’une dédiée à l’entraînement du modèle et l’autre dédiée au test.
Au sein de chaque partie, les commentaires sont équitablement dans les catégories d’intérêt (0: négatif , 1: positif).
Représentation de textes
Pour construire notre modèle d’analyse de sentiments, nous devons d’abord transformer nos textes en représentations exploitables par les différents algorithmes de prise de décision en aval.
Ici, nous optons pour une transformation standard, mais qui permet néanmoins d’extraire des informations utiles tout en filtrant les informations les moins pertinentes. Cette transformation est le Term-Frequency Inverse Document-Frequency, ou plus simplement TF-IDF, qui résume le contenu d’un texte selon la fréquence d’apparition des différents mots dans celui-ci.
En appliquant un TF-IDF à un ensemble de textes, on part d’abord des mots apparaissant dans ces textes (aussi appelé vocabulaire), puis on compte, pour chaque texte, le nombre d’occurrences de chacun de ces mots au sein du texte en question. On obtient alors le Term-Frequency (TF), un vecteur contenant les fréquences des mots apparaissant dans chaque texte.
Le vecteur obtenu pourrait suffire, cependant, utiliser les fréquences brutes a ses inconvénients. Notamment, les mots les plus fréquents (e.g. pronoms, auxiliaires, particules, …) ne sont pas réellement les plus utiles. Alors, on multiplie plutôt la fréquence de chaque mot, pour chaque texte, par une valeur qui décroît lorsque le mot apparait dans plusieurs documents à la fois. On constitue ainsi le vecteur Inverse Document-Frequency (IDF) en calculant le logarithme de l’inverse des fréquences à travers les différents textes.
L’illustration suivante schématise le protocole :
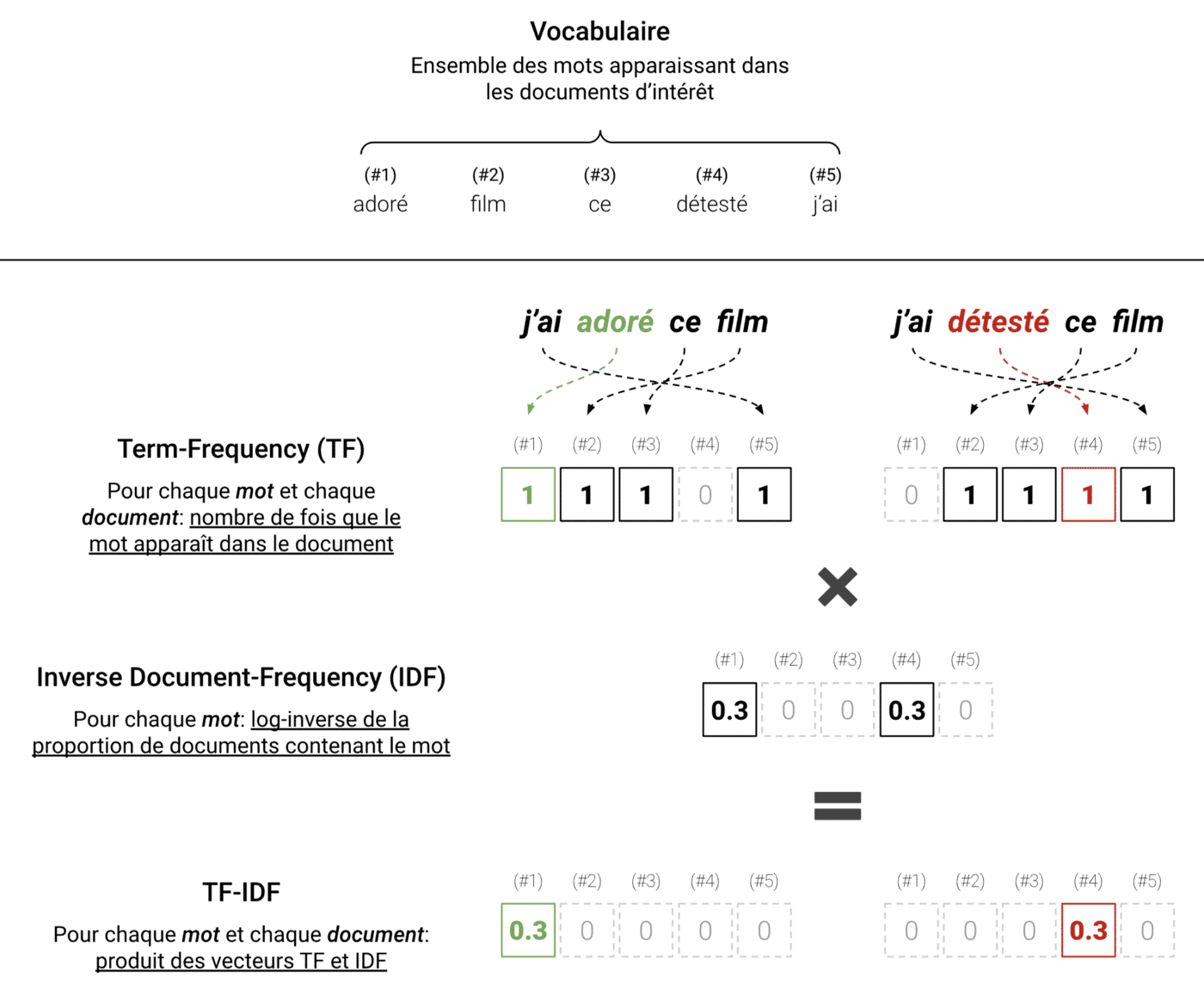
TF-IDF appliqué dans un cas simple à deux phrases. Ici, les mots importants sont “adoré” et “détesté”. On voit que le TF-IDF représente les textes en filtrant le bruit et en retenant l’information pertinente.
Dans la pratique, appliquer un TF-IDF sur un jeu de données réel est très simple. Pour cela, il suffit d’utiliser la librairie scikit-learn qui propose différents outils d’apprentissage automatique en Python.
Le Traitement Automatique des Langues est un sujet intéressant mais vaste. Dans cet article, nous nous sommes familiarisés avec différents aspects du TAL puis nous avons introduit un cas standard de classification de textes. Il reste cependant de nombreuses choses à approfondir.
Dans un prochain article, nous découvrirons les différents paramètres qu’on peut régler afin d’adapter la méthode TF-IDF à différents besoin. Nous verrons également comment utiliser ces représentations numériques pour construire un modèle capable de prendre une décision (i.e. catégoriser automatiquement nos critiques IMDb). Enfin, nous introduirons quelques concepts plus avancés qui permettront d’aller plus loin et d’appréhender l’état de l’art plus récent du Traitement Automatique des Langues.


